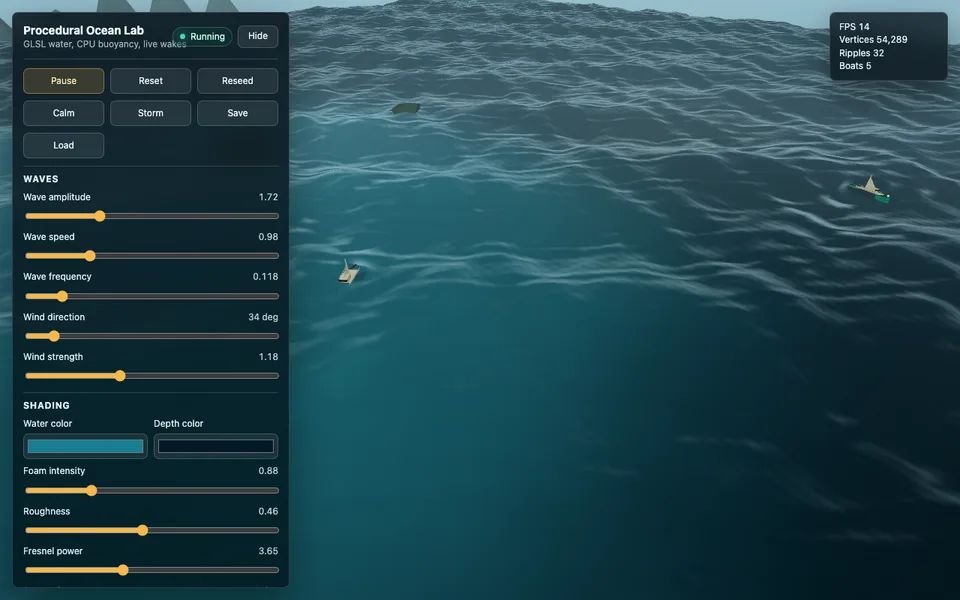
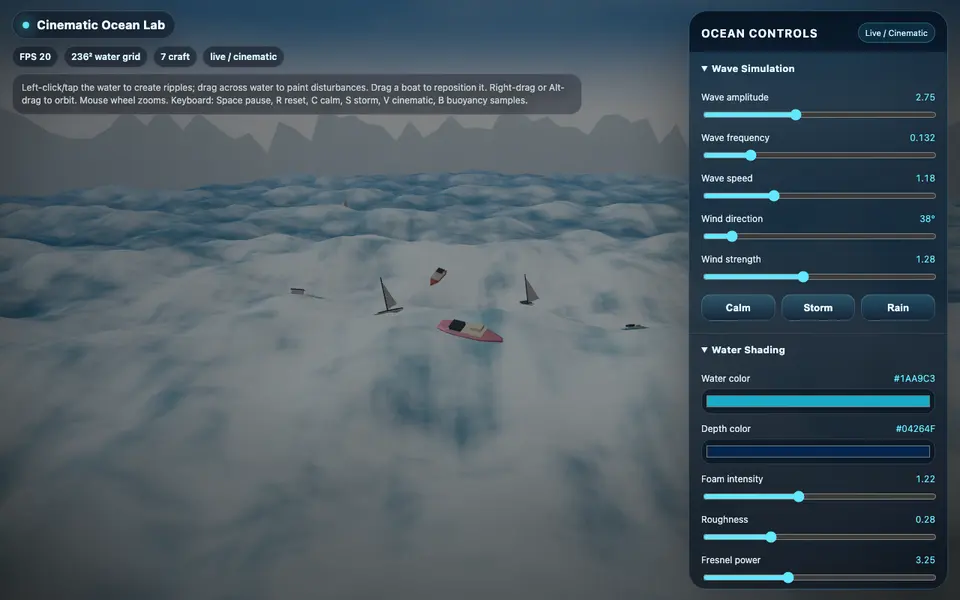
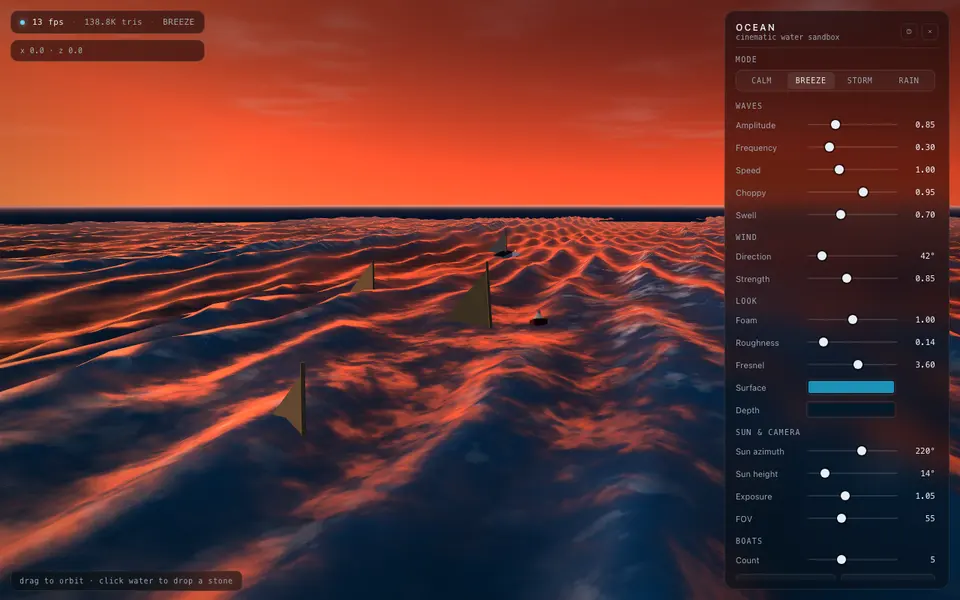
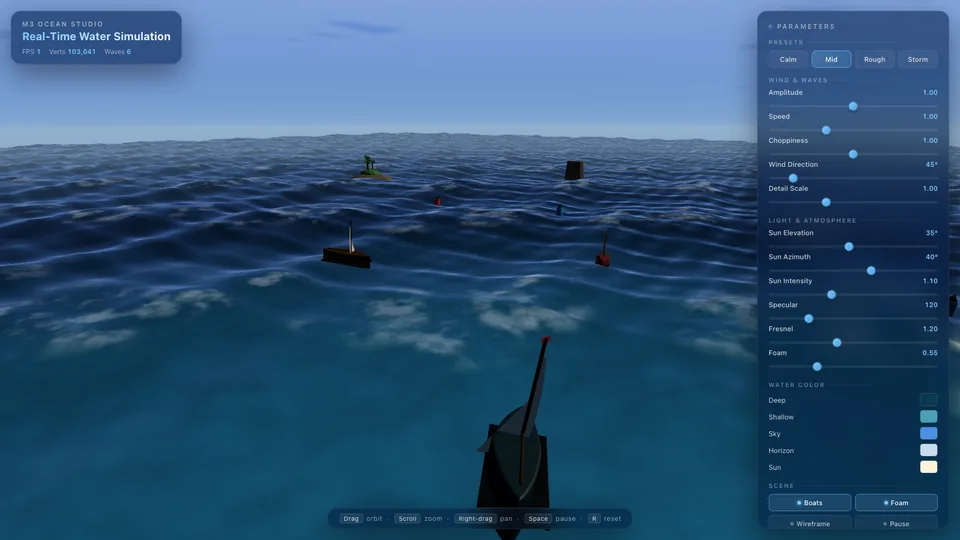
Each entry is a standalone eval page: screenshots, short judgement, and live HTML demos.
10 model lanes · 28 HTML files · screenshots attached
2 HTML demos · water shader + pelican bike · screenshots attached